Count Love: Aggregating protest data
Protests represent one method of communication between citizens and elected officials. Yet, at least in the United States, local newspaper and television reports about regional protests rarely appear in national headlines, and aggregate protest data is not readily available. The lack of aggregate protest data makes it difficult to understand singular protests in the context of longer term geographic and temporal trends. After the 2016 election, Nathan and I created Count Love in the hopes of historically documenting protests related to civil rights, immigration, racial injustice, and other important societal issues across the United States.
How Count Love Works
Count Love aims to aggregate protest data by citing primary sources—typically a news report in print or video. We manually code information about each protest, including the date that it occurred, the number of attendees, and the general topic of the protest. We use the most conservative estimate possible for attendance counts if the reported count is ambiguous. For example, we record “10” attendees if an article says “dozens of people,” or “100” attendees if an article says “hundreds.” We crawl over 1600 local newspaper and television sites across the United States in search of articles with words such as “march,” “rally,” “protest,” or “demonstration” for further review. On a nightly basis, we release a full, updated dataset of reported protests in both JSON and CSV file formats.
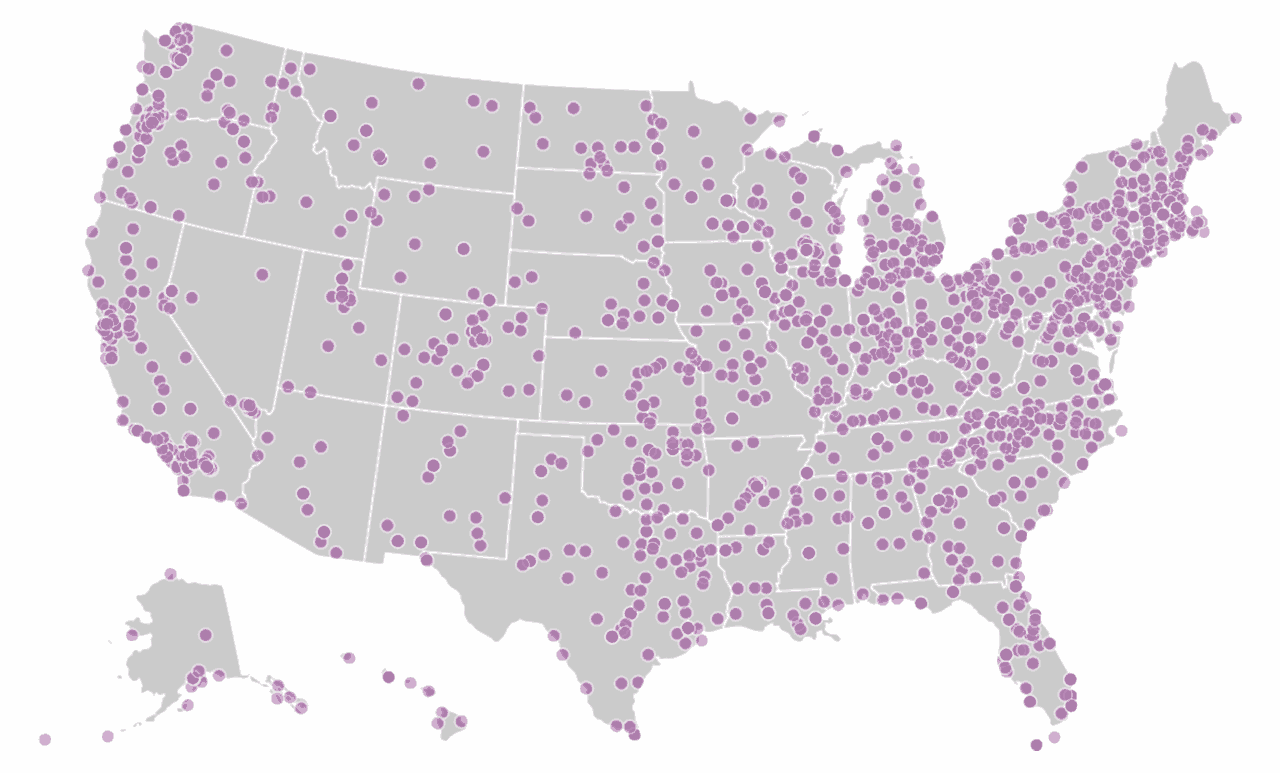
Geographic location of news sources
The software stack for Count Love, shown in the block diagram below, consists of a Python backend for crawling, extracting text, and categorizing articles; a MySQL database to store article text as well as final coded protest details; an HTML/PHP frontend to review new articles; and an HTML/CSS/Javascript frontend to display the latest dataset and statistics. We use a variety of commonly available libraries throughout our stack, including BeautifulSoup to help with text extraction, OpenStreetMap and Leaflet to draw maps, and D3.js to visualize statistics. We designed our frontend filtering tools and visualizations to dynamically update in the browser based only on the full JSON data file, to minimize load on the web server. Where possible, we automated repetitive tasks to minimize our own workload so that we could focus our manual efforts on article review—arguably the hardest step to automate with accurate results.
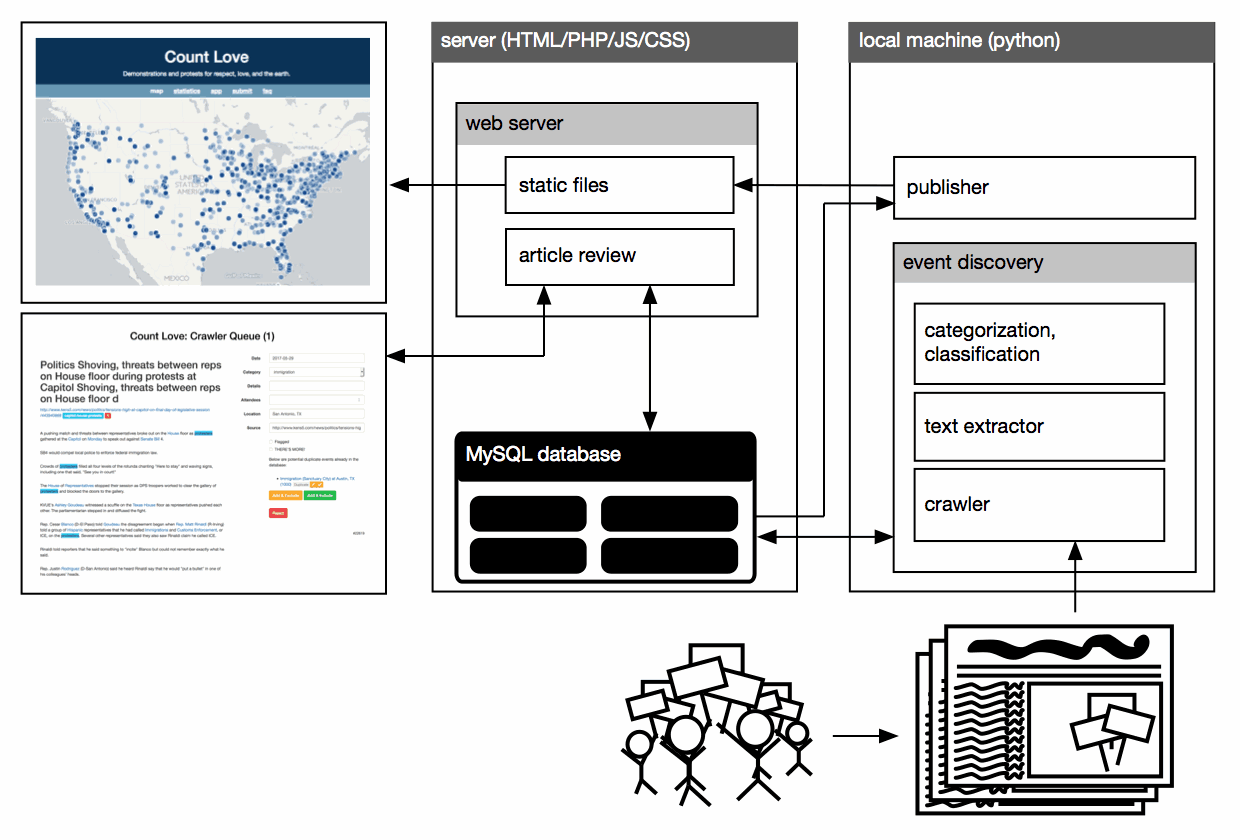
The Count Love software stack
Challenges building Count Love
Broadly, discovering and reviewing protest articles constitute the most difficult challenges for Count Love. Discovering new protests is difficult because of the vast number of news sources, and article review en masse is difficult because of its highly repetitive nature. On an average night, we review about fifty articles; on a peak night, we’ve reviewed more than two hundred. Given that there are only two of us, to make this project feasible, we spent most of our development time building tools to automate the most time-consuming and error-prone parts of our workflow. Specifically, we built tools to help with event discovery, duplicate detection, data entry, categorization, and classification.
Event discovery and duplicate detection
To visit all of our news sources nightly, we wrote a web crawler and text extractor in Python using the URLLib and BeautifulSoup libraries. After downloading articles that contain key protest words, the text extractor parses each article by scoring every text element in the document object model based on length, punctuation, and other characteristics to identify the most likely story passages. (The heuristics for scoring are inspired by Readability, which has shut down.) After parsing, the text extractor returns plain text corresponding to the news story in the downloaded file, stripped of all of its HTML formatting and markup.
After extracting an article’s plain text content, we store that content to a MySQL database, along with other information about the article, such as the date that we crawled and the original URL. We assign a unique ID to every article and every protest event. The diagram below shows key aspects of our database schema and how our backend interacts with it. We chose the database schema shown above to support the ability to cite one article (one QueueID) as the source for multiple protests, as well as to attribute one protest (one EventID) to multiple sources.
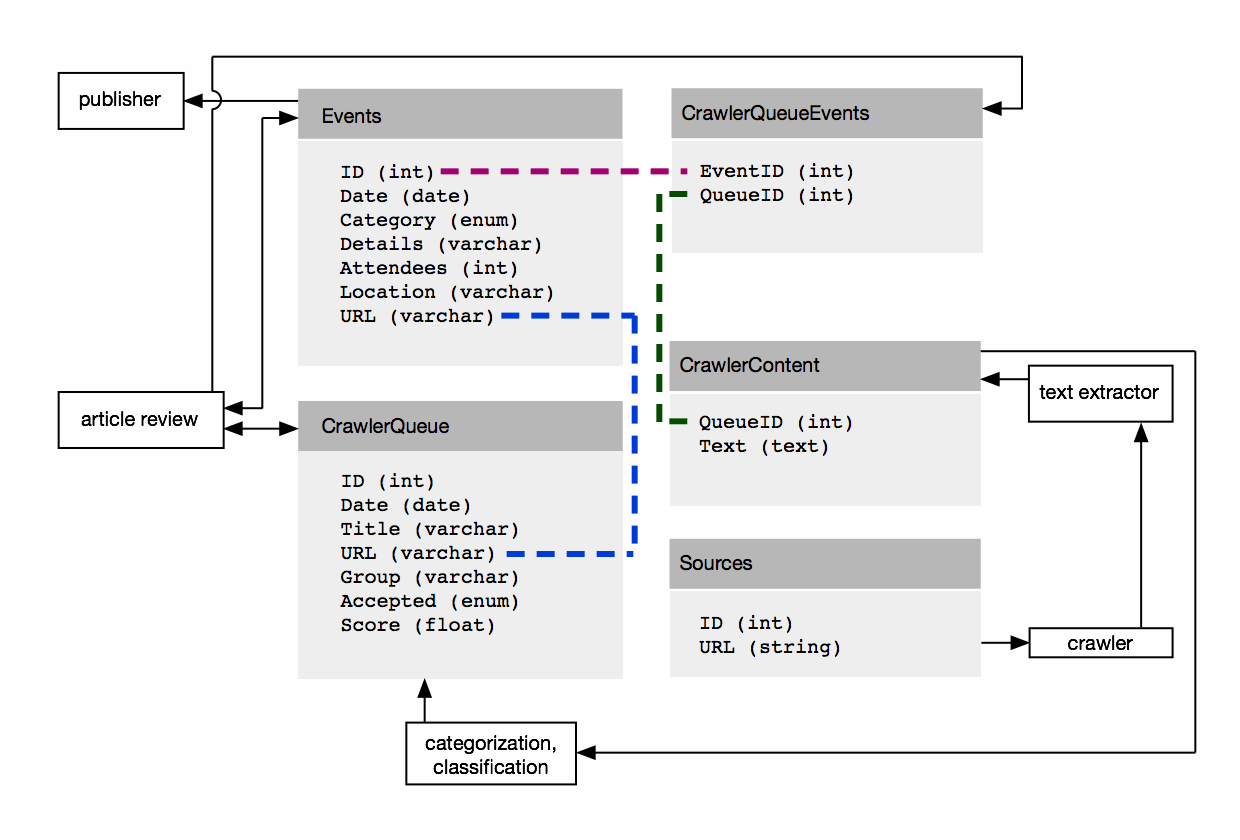
Overview of Count Love’s Database
In addition to offering flexibility with respect to adding protests and citing multiple sources, and the database schema allows us to make queries to detect potential duplicates. We attempt to identify duplicates in our dataset while crawling, during article review, and when pushing nightly data updates. During the nightly crawl, we only download articles with URLs that we haven’t encountered before. During article review, we compare the current article’s protest event to all other events in the same state and on the same day. And when publishing a new dataset, we compare the geographic proximity of all events on the same day and verify that events that occur close to one another are, in fact, distinct. We rely heavily on database queries to conduct all of these comparisons.
Data entry and article review
On any given day, data entry is the most important and error prone part of Count Love. To make reviewing articles and interacting with the database easier, we built a custom frontend in HTML/PHP/Javascript. The screenshot below shows an example of our internal article review tool. Based on simple heuristics, for each article a PHP script attempts to extract an event’s date, attendance count, location, and general topic. For example, to extract a date, the script looks for a “day of week” word like “Monday” and then chooses the most recent Monday before the article’s publication date. In ambiguous situations, the PHP script highlights potentially useful information for manual review but does not automatically fill in a field.
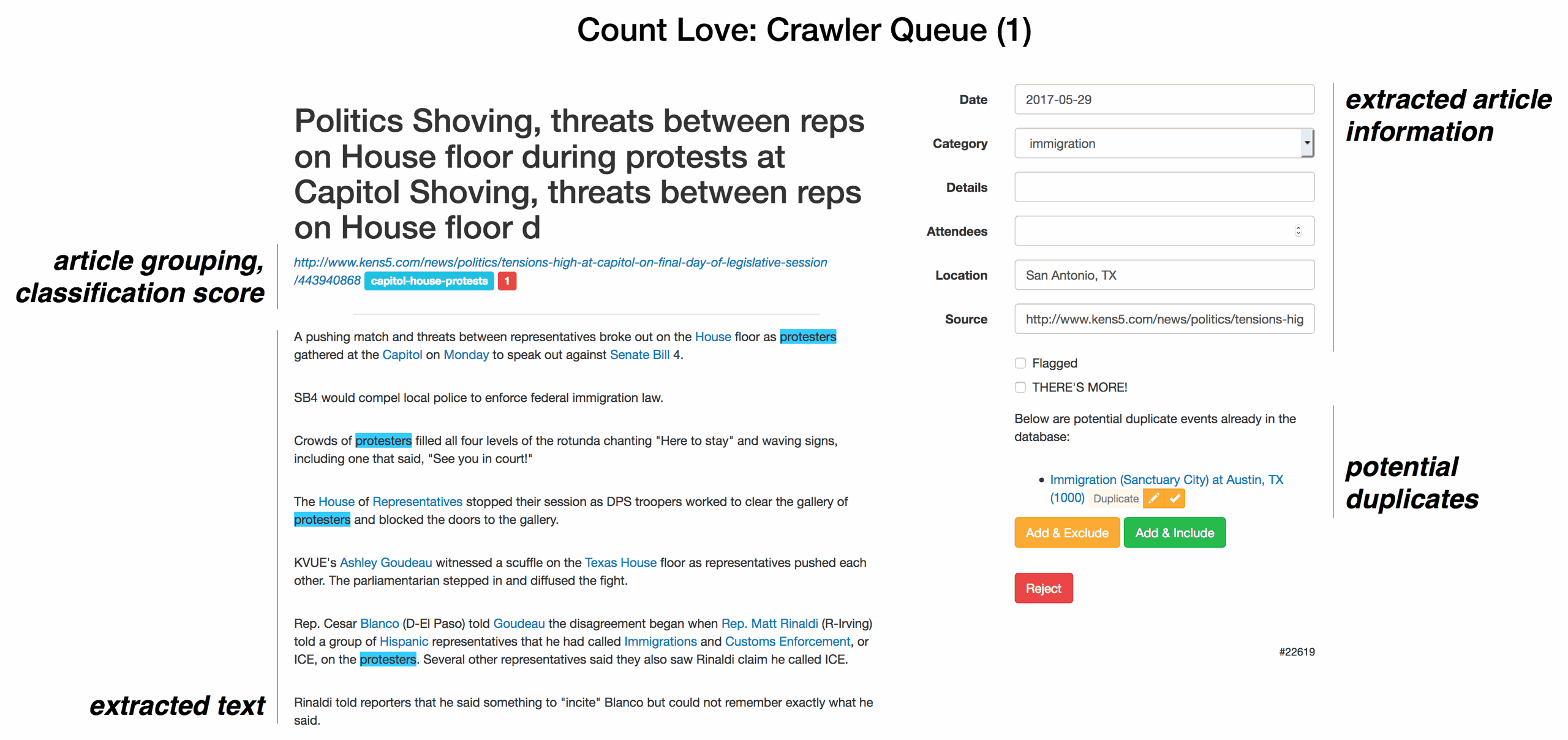
An example screenshot of the Count Love article review tool with key features annotated
In addition to preprocessing articles, the review interface also shows past protest categories that can be reused to help us consistently code protests. The interface also allows direct flagging of duplicates, or updating existing events with new information. Once we complete an article review, the PHP script updates the database and presents the next article.
Categorization and Classification
To help with article review, we also try to group similar articles together and review them in succession. To decide which articles to group together, we rely on word frequency heuristics. Each night, after downloading the text content of all articles, we generate a histogram of the most common words found that day, not including common “stop” words as defined in the Python “stop-words” library. Then, for each new article, we look through the corpus histogram until we find the three highest frequency corpus words that also appear in the article. These three words become a label for the article, and all articles with the same label are shown in succession during article review.
In addition to grouping similar articles together, we also use naive Bayesian filtering to generate an initial score that helps us decide whether to reject or accept an article. On average, we accept no more than half of all the articles that we crawl. This is because some articles are completely unrelated to protests—for example, some articles that contain the word “rally” are about sports teams, not public demonstrations. Other articles do contain actual protests, but the topic of the protest may not be one that we’re counting. The Bayesian filter score helps identify articles that we are likely to accept and reject.
To implement the Bayesian filter, we generate a corpus of unigrams and bigrams using all of our downloaded articles. We toss out rare and common n-grams using a heuristic that requires each n-gram to appear in a minimum number of articles, but no more than a fixed fraction of all articles. In the finalized corpus, we assign a unique index to every n-gram.
To calculate the probability of acceptance, we first map articles to the vector space by starting with a vector of 0’s that is the same length as the number of elements in the corpus. Then, we extract an article’s unigrams and bigrams, look up their corresponding indices in the corpus, and set those indices to 1. In this form, we can calculate an acceptance probability by taking the dot product of the article’s vector and a vector of priors, and then combine all n-gram probabilities as described in this naive Bayesian filtering article. Importantly, mapping articles to vectors opens up the possibility of sending these same data through other machine learning techniques, like logistic regression or a neural network. Both article grouping via word frequency and classification via naive Bayesian filtering have simplified the amount of time that we spend in article review, and in the future we hope to try other techniques to further minimize manual data entry.
When we started counting protests, a centralized data source did not exist for protest activity in the United States, despite significant local news coverage. We wanted to aggregate these local reports and save them to learn about trends over geography and time. We built a set of tools to save individual news reports and automated many of the repetitive steps required to discover new protest events and review news articles. We also combined heuristics and machine learning techniques to group similar articles together and make initial guesses about protest details, making the final manual review process easier for humans.